SEAR: Schema-Based Evaluation and Routing for LLM Gateways



Abstract
Evaluating production LLM responses and routing requests across providers in LLM gateways requires fine-grained quality signals and operationally grounded decisions. We present SEAR, a schema-based evaluation and routing system for multi-model, multi-provider LLM gateways. SEAR defines an extensible relational schema with cross-table consistency links and around one hundred typed, SQL-queryable signals covering context, intent, response characteristics, issue attribution, and quality scores. To populate this schema reliably, SEAR proposes self-contained column instructions, in-schema reasoning, and a multi-stage judge pipeline that produces database-ready structured outputs. Combined with gateway operational metrics, these records enable flexible SQL-based analysis, diagnosis, and routing recommendations over production traffic. Across thousands of production sessions, SEAR achieves strong signal accuracy on human-labeled data and supports practical routing decisions, including large cost reductions with comparable quality in offline replay.
Motivation
Existing approaches to LLM-as-judge evaluation fall into four broad categories, each with well-known limitations:
- Unstructured / free-text judges produce commentary that is difficult to aggregate across sessions.
- Single-score evaluators collapse all quality dimensions into one rating, preventing drill-down into specific failure modes.
- Rubric-based evaluators apply a fixed, coarse scoring scheme that does not decompose into per-signal diagnostics.
- Template-based pipelines fragment across teams and store untyped score–reason pairs that are hard to aggregate or compare.
Routing faces a parallel challenge. Learned routers optimize an objective and return a recommendation, but their decisions remain black-box, with no per-signal explanation for why a given model suits a given task. Production teams must also trade off provider, cost, latency, and throughput explicitly, and typically prefer asynchronous policy refresh with offline validation over opaque per-request routing.
System Overview
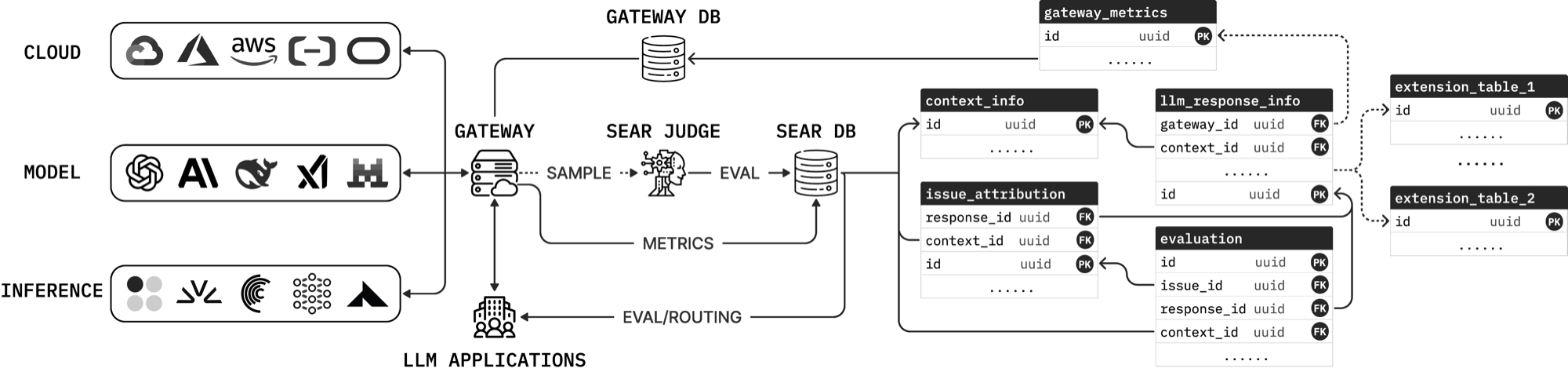
A central LLM gateway sits between applications and providers. Every request logs operational metrics (latency, time-to-first-token, token counts, cost, cache usage, error type) to a gateway_metrics table. A configurable fraction of traffic is sampled off the serving path and sent to the SEAR judge, a reasoning-LLM pipeline that writes structured signals into four semantic evaluation tables:
context_info(45 columns): request-side context and user intent, including language, domain, task type, and requirements like tool use, code, or multi-step reasoning. Includes 20 static features (modality flags, message and token counts) derived directly from raw logs.llm_response_info(19 columns): what the model actually produced, including tool invocation, code generation, reasoning behavior, and refusals. Overlapping dimensions withcontext_infoenable gap analysis ("code requested but not produced").issue_attribution(20 columns): for each shared dimension, attributes gaps to their likely source: user input, context, model behavior, or mixed causes.evaluation(31 columns): ordinal severity per signal and overall quality dimensions (relevance, completeness, coherence, instruction following, factual accuracy, safety, overall quality).
All columns are typed: booleans, categorical enums, or ordinal enums with explicit level definitions. Integer and floating-point scores are deliberately avoided, since prior work shows LLM judges cluster and degrade on wide numeric scales (e.g., 90 vs. 93).
Cross-table Design
The four tables mirror one another along semantic dimensions. For a signal family such as tool_call, the schema records whether tool use was required, whether it was produced, who is responsible for any gap, and how severe the gap is. Two properties follow directly from this design:
- Consistency checks. Disagreements across linked columns surface as SQL join violations. Flagged records can then be re-judged with a stronger model or filtered out.
- Signal traceability. Each signal can be traced through all four tables, from request to response to attribution to severity.
Schema-Conforming Judge Pipeline

Generating a hundred-column structured output in a single call is unreliable. SEAR addresses this with three design choices:
- Self-contained column instructions. Each column description specifies its definition, evidence scope (which messages to inspect), value-assignment rules, examples, and edge cases that separate it from neighboring columns. This reduces inter-column interference during generation.
- In-schema reasoning. Rather than a separate chain-of-thought call (which doubles the number of LLM invocations from four to eight for the full schema), SEAR places a temporary
reasoningtext field as the first property of the JSON schema. Because generation follows schema order, the model emits reasoning before the signal columns in a single autoregressive pass; the field is dropped before database insertion. The reasoning prompt is structured as a self-check: identify the task, derive signals step by step, and verify consistency. - Multi-stage pipeline. Tables are generated in foreign-key order (context → response → attribution → evaluation), each stage receiving the conversation plus all upstream structured outputs. Each call emits 19–31 columns instead of roughly one hundred, improving generation stability.
Data-Driven Evaluation
Because evaluation signals and gateway metrics live in the same queryable layer, downstream analyses reduce to standard SQL:
- Model evaluation joins issue-attribution and severity columns from the evaluation tables with the gateway table to compare candidate models along any task-type or domain slice (e.g., coding tasks over the last thirty days).
- Provider evaluation ranks providers on task quality with median latency as a secondary criterion, for any workload.
- User evaluation aggregates user-side risk indicators (safety-sensitive content, ambiguous instructions, noisy context) to trigger guardrails or adjust sampling rates.
Because records are timestamped, the same queries can be windowed to track temporal trends and detect model or provider drift.
Data-Driven Routing
The same records also drive routing. Rather than a black-box per-request classifier, SEAR derives policy updates from accumulated observations:
- Model routing. For a given slice and quality–cost trade-off, recommend the cheapest model whose aggregate quality is within a target margin of the best-performing model (or that outperforms a currently deployed baseline).
- Provider routing. For a given model, select providers whose quality is within 5% of the best and rank them by median time-to-first-token.
This asynchronous pattern matches production practice: offline recommendations that can be reviewed, replayed, and validated before deployment, rather than opaque per-request decisions on live traffic.
Experimental Results
We evaluate SEAR on 3,000 production sessions drawn from three organizations (A, B, and C), with distinct workload profiles (multilingual, roleplay, and translation-heavy, respectively). 300 sessions (100 per organization) are held out and fully human-annotated across all semantic evaluation columns by two senior engineers.
Judge Accuracy
Across six configurations (GPT-5-mini and GPT-5.2 at low/high reasoning effort, with and without in-schema reasoning), the best configuration — GPT-5.2 at high reasoning effort with in-schema reasoning — achieves:
- Error rate 0.0851, Hamming loss 0.0794
- Boolean accuracy 95.5%, boolean micro-F1 0.899
- Categorical accuracy 93.4%
Broken down by table, boolean-signal accuracy exceeds 91%, categorical-signal accuracy exceeds 92%, and ordinal-signal accuracy ranges from 80% to 86%.
Routing Case Study
For Organization C, where most traffic falls into a simple-complexity slice currently served by claude-haiku-4-5 ($1.00/M input, $5.00/M output), SEAR's routing query ranks candidates by composite quality (the sum of six ordinal quality signals, maximum = 18):
| Model | Quality | $/M in | $/M out |
|---|---|---|---|
| gemini-2.5-flash-lite | 17.57 | 0.10 | 0.40 |
| claude-haiku-4-5 (deployed) | 17.00 | 1.00 | 5.00 |
| grok-4-1-fast | 16.86 | 0.20 | 0.50 |
| qwen3-80b | 15.66 | 0.15 | 1.20 |
Replaying 100 sessions with the top-ranked candidate and comparing outputs pairwise against the deployed model yields 72 ties, 12 wins for the routed model, and 16 wins for the original, indicating effectively tied quality at 90% lower input cost and 92% lower output cost.
This result should be interpreted as a targeted case study rather than a definitive benchmark — one organization, one workload slice, and an offline replay of 100 sessions. Even so, it demonstrates that SEAR-derived queries can identify substantially lower-cost candidates without clear quality degradation, and that logged traffic is sufficient to drive offline policy updates even with limited data.
Full Schema

Discussion
Co-locating evaluation signals and gateway metrics in a single SQL-queryable data layer enables a closing feedback loop: SEAR signals accumulate, routing policies are refreshed from those signals, routed traffic generates new signals, and quality estimates improve over time. Because judging runs asynchronously on sampled traffic off the serving path, stronger (and slower) judge models can be used without affecting request latency. We view the combination of a typed relational schema, schema-conforming generation via in-schema reasoning, and foreign-key-ordered multi-stage decomposition as a principled foundation for flexible, interpretable LLM evaluation and routing in production gateway settings.